-
随着地表矿、浅部矿及易识别矿的日益减少,找矿工作难度不断增加。因此,地质工作者越来越重视对找矿预测新方法、新技术的研究,期待实现找矿新突破。传统的矿产资源预测基于成矿理论,从矿床成因出发,依靠采样数据和固有的模型和模式进行分析、预测,虽然存在大量的各类信息资源,但其全面利用和综合分析能力不足,不足以对成矿信息进行系统的关联分析,从而使预测方法发挥作用有限,效果往往不是十分理想(周永章等, 2017;2018)。赵鹏大等(2015)提出数字找矿的概念,将大数据概念引入地学领域,实现了数学地质到数字地质的飞跃,弥补了传统定性找矿的缺陷。
利用大数据和机器学习解决矿产预测问题,有助于人们克服不能全面考虑地质变量的困难及评估当前模型在已有数据中的可靠性(刘艳鹏等, 2018)。大数据方法以数据为出发点,分析多源、异构数据的相关关系,从而挖掘隐藏信息。大数据要全体不要抽样、要效率不要绝对精确、要关联不要因果的技术取向(张旗等, 2017),其对于突破采样随机性和样品空间狭小、大量良莠难分的非结构化和半结构化数据无法利用,以及可靠的作用机理、因果关系和动力学模型缺乏,仅凭少量观测数据和固有模式进行判断、预测等限制,无疑有极大的好处(吴冲龙等, 2016)。机器学习是一门涉及概率论、统计学、逼近论等多领域的交叉学科,正逐步被应用到矿产资源定量预测评价中,其对地质大数据进行属性和特征学习,在不同变量与已知矿体之间建立某种映射关系,再利用这种映射关系对未知区进行预测。自20世纪90年代以来,GIS技术蓬勃发展使综合信息矿产评价变得切实可行并广泛应用在成矿预测领域,K邻近(吴春明等, 2012)、证据权(陈广洲等,2010;高曙光等, 2010;杨佳佳等, 2016)、神经网络(Rumelhart et al., 1986;苗国文等, 201;赵兴东等,2023)、支持向量机(Abedi et al., 2012;Chen et al., 2019)和随机森林(Rodriguez-Galiano et al., 2014;Carranza, 2015;欧阳渊等, 2023)等强大的数据驱动方法实现了成矿要素异常识别与找矿远景区圈定。基于机器学习开展的多源地学成矿异常要素的提取、训练、预测、集成、综合解译的方法,有望实现找矿新突破。
随机森林作为一种典型的机器学习算法,因其天然的并行特性,良好的模型可解释性,优秀的鲁棒性和泛化特性而被广泛应用于矿产资源预测(Breiman, 2001;Carranza, 2015;张士红等, 2020;Cao et al., 2023;Josso et al., 2023)。随机森林通常是多棵决策树的一种集成,在成矿预测中,决策树根据调节已知样本各项特征的使用个数和分割顺序的先后,且对其施加不同的阈值实现最有效的分割,然后再集成多棵树的分割优势,同理将这些训练好的树用于未知区的预测。
已有研究结果表明,随机森林在矿产资源预测中的有效性优于支持向量机、人工神经网络、证据权等方法(Rodriguez-Galiano et al., 2015;Sun et al., 2019;李苍柏等, 2020;Yang et al., 2022)。Carranza等(2015)证实随机森林模型可用于已知矿床点分布较少的区域找矿预测,并能有效处理带有缺失值的数据,对比研究结果显示在菲律宾阿布拉地区斑岩铜矿预测中,随机森林预测结果优于证据权。欧阳渊等(2023)利用随机森林在冈底斯成矿带西段圈定出11个斑岩-浅成低温热液型铜多金属矿找矿远景区,并指出基于大数据机器学习的欠采样随机森林预测模型,能有效处理综合地物化遥信息的预测数据高维和极不平衡特点。Yang等(2022)通过卷积自编码器网络并行挖掘预测变量的潜在高级特征后,采用支持向量机、逻辑回归、人工神经网络和随机森林开展了中国南秦岭凤县地区的金矿预测,结果表明随机森林预测结果与实际更一致,且在更小的勘探区捕获了更多的金矿。Josso等(2023)采用随机森林有效开展了世界海洋铁锰结壳的矿产资源预测,并指出在国际海底管理局许可区域,随机森林在预测高成矿概率区域的准确性相对于GIS方法更高。
下雷-土湖是中国著名的以碳酸盐岩为容矿围岩的沉积型锰矿成矿区,区内产出中国首个超大型锰矿床—下雷锰矿。众多学者对下雷-土湖地区开展了大量研究工作,查明了典型矿床的地质特征(金玺等, 2018;卢安康, 2022;邓军等, 2023)、矿石矿物组合(朱建德等, 2016)、成矿物质来源(莫斯霖, 1985;王荣庚, 2012;黄明富等, 2014)、矿床成因(郝瑞霞等, 1994;李毅, 2008;欧莉华, 2013;杨威等, 2015)。一些学者在该区开展了单学科找矿预测(徐丽华等, 2011;谢华等, 2016)。闫芳(2012)以GIS为平台,采用回归分析和证据权开展了该区的多元信息找矿预测,圈定了预测远景区。该区以往的找矿预测以规则传统定性、半定量为主,不能充分反映锰、铝成矿物质在短时间内巨量堆积这一复杂的非线性过程。基于地学大数据机器学习的找矿预测,是以数据为中心从中挖掘找矿信息并进行融合,弥补了传统预测方法的不足,有望实现找矿预测质的飞越。本文以下雷-土湖地区沉积型锰矿为例,基于随机森林算法,深入挖掘Mn元素、沉积相、上泥盆统榴江组和五指山组出露、重力、航磁及向斜的空间分布特征及其与锰矿矿床的空间的耦合相关性,以及不同控矿要素之间的相关性,构建二维矿产预测分类模型,进行分析、预测并圈定成矿远景区。
1地质背景1.1区域地质背景和矿床地质特征研究区位于广西壮族自治区西南部,桂西南地区大地构造位置属扬子板块西南缘,南华活动带西南部,位于古特提斯构造域和环太平洋构造域的复合部位,是南盘江-右江成矿区的重要组成部分(徐丽华等, 2009)。研究区主体位于右江褶皱带东南部,早古生代属于扬子准地台与华南地槽的过渡区,二级大地构造单元处于扬子克拉通(Ⅳ-4)西南缘,三级构造单元为滇黔桂被动陆缘带(Ⅳ-4-3),属于富宁-那坡陆缘沉降带(Ⅳ-4-3-2)中的下雷坳拉谷(Ⅳ-4-3-2-3),位于受广南-那坡同沉积断裂控制的那坡-龙州裂谷带内(胡超, 2011;欧莉华, 2013)(图1a)。研究区出露地层除了新生界第四系,还出露早古生界寒武系,以砂、泥岩复理石建造为主;晚古生界泥盆系、石炭系及二叠系,主要为台地相碳酸盐岩建造及台盆-斜坡相硅质岩夹碳酸盐岩建造;中生界三叠系,主要为开阔台地相-局限台地潮坪相灰岩-白云岩建造。其中,晚古生界在工作区出露面积最大,出露较全;晚泥盆世五指山组和榴江组为锰矿主要的赋矿地层(图1b)。
研究区泥盆纪沉积环境呈现台盆相间格局的特点,从中泥盆世晚期开始,由于基底断裂活动或是海底扩张作用,形成了2个不同的沉积体系,即半局限台地沉积体系和台沟沉积体系(叶太平等, 2021)。台盆沉积体系是研究区锰矿形成的有力场所。区内最主要的褶皱构造为NNE-SWW向展布的下雷-上映向斜。矿集区断裂发育,主要由NNE向、NW向2组断裂,其中最具代表性的断裂构造为下雷-上映同沉积断裂以及黑水河活动性断裂。矿集区岩浆岩活动较弱,仅发育少量岩墙、岩脉、岩株,以晚古生代基性岩为主,次为中生代超基性岩。研究区内锰矿资源最为丰富,素有锰都之称,产出下雷、湖润、土湖、上映等大型-超大型矿床,累计查明资源储量2. 085亿吨,占广西锰矿总量的70.33%,氧化锰矿石的品位一般为10%~40%,碳酸锰矿石的品位一般为12%~28%(何海洲,2014)。其中下雷锰矿床最有名,被称为“下雷式”锰矿。研究区的锰矿主要形成于晚泥盆世,该时期的锰矿储量占广西锰矿储量的80%以上。
研究区的锰矿体常呈层状、似层状产于晚泥盆世五指山组第二段和榴江组第二段地层中,产状与围岩产状大体一致。围岩蚀变以蔷薇辉石化、菱锰矿化、硅化、含锰碳酸盐化、黄铁矿化为主。矿石类型分为碳酸锰矿石和氧化锰矿石。前者的矿石矿物主要为锰方解石、钙菱锰矿,次为蔷薇辉石、锰帘石、褐锰矿;脉石矿物主要为石英、方解石、高岭石、水云母和黄铁矿,含少量的绿泥石、绢云母、碳质、透闪石、阳起石、黄铜矿、褐铁矿、白铁矿和白钛矿等。氧化锰矿石主要的矿石矿物有锰钾矿、硬锰矿、软锰矿、恩苏塔矿、偏锰酸矿;脉石矿物有石英、玉髓、高岭石、水云母及少量蒙脱石、水黑云母、绢云母等。
1.2区域找矿模型在以往研究的基础上,文章全面总结了区域成矿规律,综合研究区的地球化学和地球物理特征,查明了控矿要素与找矿标志,构建了区域找矿模型(表1)。找矿模型包括大地构造位置、区域成矿带、成矿时代、岩相古地理、沉积建造、含锰岩系、蚀变特征、成矿构造及成矿结构面、地球化学标志和地球物理标志等10个要素。其中,前7个要素在区域地质背景中已经论述,在此补充其余3个要素内容。
成矿构造及成矿结构面:下雷-土湖同沉积断裂带内次级同沉积断层既控制次级成锰裂谷盆地的生成,也控制着深部富锰热液的运移通道,富锰热液沉积界面即成矿结构面。
地球化学异常:由于研究区的矿石矿物主要为锰方解石、钙菱锰矿,次为蔷薇辉石、锰帘石、褐锰矿等,均为含Mn的矿物,因此,本次研究中的地球化学异常主要指Mn地球化学异常。Mn异常的浓集中心与矿床地表氧化锰的分布基本一致,呈现由向斜扬起端及两翼组成的“V”字型高异常带。深部碳酸锰的分布区Mn地球化学异常一般要低于氧化锰,可以结合地层、构造为深部找矿提供依据。
地球物理异常:主要指布格重力异常和剩余重力异常。重力异常梯度带是岩石组合和地质构造的综合反映,能在一定程度上指示不同岩性界面或断裂带。研究区异常过渡带呈北东走向分布,与本区的成矿构造(同沉积断裂带内次级同沉积断层)基本吻合,已知的锰矿床多位于重力高异常与重力低异常的过渡带上,如下雷锰矿,其西侧为剩余重力低异常,东侧为剩余重力高异常。
2方法和数据基于随机森林算法的二维找矿预测流程如图2,包括通过查明控矿要素和找矿标志,构建找矿模型;采用统计分析、缓冲区分析和空间插值分析提取预测要素,建立随机森林模型开展找矿预测三大主体内容。
2.1预测要素提取预测要素的有效提取是实现数据化到信息化的必要技术手段,也是开展找矿预测的前提。本文采用统计学分析、缓冲区分析和空间插值分析等方法进行多源异质异构预测要素的提取。本次提取的预测要素主要包括赋矿地层、沉积相、控矿构造(向斜)、蚀变特征(锰矿露头缓冲区)、水系沉积物地球化学特征(Mn元素空间分布)、剩余重力异常特征、布格重力异常特征和航磁ΔT化极异常特征。
预测要素的具体提取过程如下。①赋矿地层:提取上泥盆统五指山组、榴江组分布的区域,分别赋值为类别1和类别2,其他地层分布的区域赋值为类别0 (图3a)。②研究区的沉积相包括河流相砂砾石与砂泥质沉积、台地边缘相碳酸盐岩沉积、半局限台地相白云岩夹碳酸盐岩相、台地内部相碳酸盐岩沉积、台地内部至边缘相碳酸盐岩夹硅质岩泥砂质沉积、滨岸砂泥坪相泥岩与砂岩沉积、盆地相盐酸盐岩夹硅质岩沉积、台地内部相碳酸盐岩硅质岩与泥岩沉积和盆地相砂泥质夹碳酸盐岩沉积,从类别1~9分别进行赋值(图3b)。③蚀变特征:基于锰矿露头的分布,综合考虑露头附近地层的产状和目前开采的最大深度,确定露头缓冲半径。依据露头附近地层的倾向,确定缓冲方向。由于露头附近地层的倾角主要集中在10°~84°,平均值为45.73°,目前可开采的最大深度为1000 m (赵品忠等,2021),通过换算,在1∶50 000的图中,露头的缓冲半径为20 mm(图3c)。④锰矿的产出主要受向斜控制,本次工作以向斜轴为中心,通过将向斜两翼赋矿地层(上泥盆统五指山组/榴江组)的底界线相连,形成一个不闭合的区间,依次作为向斜的缓冲区。不同的向斜,其缓冲面积不同(图3d)。⑤水系沉积物的锰元素含量、布格重力、航磁ΔT化极和剩余重力均采用反距离加权插值,转化为栅格数据(图3e~h)。
2.2随机森林算法随机森林是在美国加州大学Leo Breiman (1996)发表的Bagging集成学习理论和Tin Kam Ho (1998)提出的随机子空间(Random Subspace)方法的基础上,基于CART(Classification And Regression Tree)决策树的组合分类模型算法。随机森林可以同时处理连续变量、离散变量和混合型变量。它将多种弱分类器集成为一个强分类器,决策树输出类别的众数或平均数决定了输出分类,该算法对特征选取具有较好的鲁棒性,无需特征筛选也能得到较高的准确率,是一种高效率的有监督机器学习算法(Breiman, 2001)。该方法的优点是:①随机性强,不易过拟合,抗噪性强,对异常点不敏感;②随机抽取一部分数据进行训练,处理高维数据相对更快;③树状结构,模型可解释度高,可以给出每个特征的重要性;④对于不平衡数据,随机森林可以平衡误差。随机森林算法的具体过程如下:
(1)从原始样本集中有放回的随机抽取N个训练样本,共进行k轮抽取,得到k个训练集(k个训练集之间相互独立,元素可以重复);
(2)对于k个训练集,构建k棵决策树模型并对其进行训练,其中每棵决策树的特征项的数目和顺序都是随机的,对抽到的特征找到基尼指数最小的分裂阈值应用于节点分裂,直到这棵树最大限度的生长;基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。假设由k个类别,第k个类别的概率为pk,则基尼系数的表达式为:
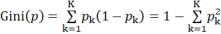
(3)将训练好的模型用于预测未知区的数据,根据输出结果的性质(离散还是连续)可分为分类问题和回归问题,对于分类问题由投票表决产生分类结果,对于回归问题由k个模型预测结果的均值作为最后预测结果,所有模型的权重相同。
随机森林算法既可以用于解决分类问题,也可用于解决回归问题。对于分类问题,最常见的评价指标是基于混淆矩阵的准确率,精度,召回率和F1值。
混淆矩阵是主要用于比较分类结果和实例的真实信息。对于成矿预测的二分类(含矿与不含矿)问题,其混淆矩阵如表2所示。表2中,TP表示预测为含矿且实际也为含矿的样本数,FP表示预测为含矿但实际为不含矿的样本数,FN表示预测为不含矿但实际为含矿的样本数,TN表示预测为不含矿且实际也为不含矿的样本数。
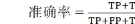 (1)
(1)
 (2)
(2)
 (3)
(3)
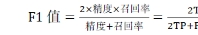 (4)
(4)
 (5)
(5)
准确率是所有预测正确的样本数占总样本数的比例;精度是正确预测为含矿的样本数占全部预测为含矿的样本数的比例;召回率是正确预测为含矿的样本数占全部实际为含矿的样本数的比例;F1值为精确率和召回率的调和平均值;特异性为正确预测为不含矿样本数占全部实际为不含矿的样本数的比例。
2.3随机森林算法数据处理过程由于地质、地球化学和地球物理等要素图层具有不同的格式和坐标系,因此需要进行格式转换、坐标统一与配准。结合下雷-土湖地区矿床分布特征和数据特点,将研究区按照5.67×5.67的单元格大小进行剖分,得到21 181个单元格,并对每个单元格进行地质、地球化学和地球物理等特征的赋值,每个单元格代表1个样本。
随机森林算法需要从给定的训练数据集中学习到一个最优的模型,再利用这个模型将新的输入映射为相应的输出,以达到分类目的。训练数据包含正负样本,且正负样本数量应相对一致,以防止过拟合和欠拟合。本文中的正样本为含矿样本,含矿样本取部分见矿钻孔及矿体露头单元,负样本为非含矿样本。通常在选择训练样本时遵循以下3个原则:①非含矿单元与含矿单元数量相当;②非含矿单元与含矿单元之间有一定的距离;③非含矿单元应该在空间上服从随机分布(Carranza et al., 2015)。由于研究区的含矿样本数远低于非含矿样本数,因此在构建训练子集时加入了类权重参数,以此来平衡含矿样本和非含矿样本的数量。假设有k个类别,第i类的权重参数依据以下公式获得:
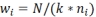
其中,N表示总样本量,ni表示第i类样本的个数。
本文选取了1932个样本作为训练集,采用类权重参数构建平衡子集,用于训练模型,另外选取了484个样本作为测试集,不参与模型训练,用于评价模型的精度(图5)。
在随机森林算法建模的过程中,决策树数量、树深度、节点分裂所需的最小样本数及每个叶子节点所需的最小样本数等超参数的设置直接影响了模型的效果。通常,决策树数量越多,误差越小;但数量过多会导致计算冗余。决策树深度、节点分裂所需的最小样本数及每个叶子节点所需的最小样本数等3个参数偏小或偏大会导致欠拟合或过拟合(Nadi et al., 2019)。树节点的特征变量数量同样影响预测效果。为了保证训练效果,引入交叉验证和袋外准确率得分来综合确定最佳超参数组合。本研究中采用超参数为:树的棵树为35,每棵树的最大深度为8,节点分裂所需的最小样本数为4,每个叶子节点所需的最小样本数为1,每个决策树的最大特征数为4。同时,通过有放回的随机取样,确保每棵树的训练样本都是从原始数据集中有放回地随机抽取的,以上超参数的设置在保持模型复杂性的同时提高其泛化性能。最后将训练好的模型用于未知区数据进行预测,用每棵决策树预测结果的平均数作为预测概率结果。
3分析结果与讨论3.1模型的准确性随机森林模型验证结果表明,测试集中的484个样本中,59个预测为含矿单元,425个预测为不含矿单元,没有被错分的样本,这与真实值完全一致。依据混淆矩阵得到精确度、召回率、F1值、特异性均为1.00(表3),依据模型获得的袋外准确率得分为0.998,表明该模型的泛化能力和对未知数据的预测能力十分优异。
3.2特征重要性随机森林提供了一种内置的算法来计算每个特征的贡献(Breiman, 2001)。特征重要性可以通过计算每个特征在所有决策树中基尼系数的平均值来得到。一个特征的特征重要性值越高,其对预测结果的影响越大。
本文基于随机森林方法获得的预测变量特征重要性排序如图6所示。在特征重要性排序中,前4个特征分别为赋矿地层、沉积相、Mn元素异常和锰矿露头缓冲,重要性占比分别为32.52%、26.07%、19.50%、10.35%,合计占比88.43%,表明这4个特征对研究区锰成矿的影响较大,赋矿地层和沉积相为主要的控矿要素,Mn元素异常和锰矿露头缓冲为重要的找矿标志,这与地质认识一致。
3.3找矿远景区圈定与评价基于随机森林的预测结果,统计分析已知正样本与预测得到找矿远景区(预测结果大于0.5)的面积关系,形成累积捕获比率图(图7),用于评价模型的有效性,并为圈定新的找矿远景区提供依据。累积捕获比率图的横坐标表示大于等于某一预测值的找矿远景区占总找矿远景区(预测结果大于0.5)的比例,纵坐标表示大于等于某一预测值的找矿远景区中已知正样本所占的比例。图7表示了累积的正样本捕获比率随着预测值的变化,曲线迅速达到了较高的y值,意味着模型能够用较小的找矿预测区域比例捕获到较高的实际矿化区域比例。通过对随机森林(RF)、逻辑回归(LR)及支持向量机(SVM)算法预测结果的比较,可以看出,虽然开始3种算法都能在非常小的预测区范围内能够迅速的捕捉实际矿化单元,但随着预测区范围逐渐变大,支持向量机和逻辑回归算法在识别已知矿化单元中存在局限性,最终预测出已知矿化单元的97%,而随机森林在预测区约30%时,便识别出了所有已知矿化单元。
此外,从图7中可以得到随机森林预测结果概率值为0.9和0.75两个明显的分界点。当预测值为≥0.9时,曲线的斜率较大,捕获实际含矿样本的比例呈快速增长模式;当预测值≥0.75小于0.9时,曲线的斜率减小,捕获实际含矿样本的比例呈缓慢增长模式;当预测值<0.75时,曲线的斜率近似于0,捕获实际含矿样本的比例基本不变。因此,将预测值为0.9和0.75用于圈定找矿远景区的依据。基于此,圈定了6个找矿远景区,并根据预测值划分了远景区等级(表4,图8)。
Ⅰ类找矿远景区的预测概率均>0.9,主要分布于坡净南部(Ⅰ1)、那国村-三叠岭地区(Ⅰ2)和但山-岜排后地区(Ⅰ3)。这些区域的地层均为上泥盆统五指山组,沉积相为台地内部相碳酸盐岩、硅质岩与泥岩(Ⅰ1、Ⅰ3)或夹硅质岩、泥砂质沉积(Ⅰ2)。w(Mn)普遍较高,Ⅰ1为3200×10⁻⁶到3709×10⁻⁶,Ⅰ2为2214×10⁻⁶到3014×10⁻⁶,Ⅰ3为2914×10⁻⁶到3014×10⁻⁶。Ⅰ1距离锰矿露头缓冲区约0.1 km,Ⅰ2为0.7 km,Ⅰ3为3.9 km,且这些区域均处于重力与航磁异常带,呈现较为明显的矿化特征。
Ⅱ类找矿远景区的预测概率大于0.75,分布于龙火岭东部(Ⅱ1)和意江村北部(Ⅱ2)。这些区域出露地层为上泥盆统五指山组(Ⅱ2)或榴江组(Ⅱ1),w(Mn)范围从2414×10⁻⁶到3314×10⁻⁶(Ⅱ1)和2014×10⁻⁶到2214×10⁻⁶(Ⅱ2)。Ⅱ1距锰矿露头缓冲区约14 km,Ⅱ2为19 km。Ⅱ1区域位于重力低异常带,而Ⅱ2则位于重力高异常与低异常的过渡带。
Ⅲ类找矿远景区的预测概率>0.75,位于仰屯村东部,出露地层为上泥盆统五指山组,w(Mn)均值为1314×10⁻⁶。该区位于剩余重力高异常与低异常的过渡带,且距离锰矿露头缓冲区约6 km,整体位于那样-下谜向斜缓冲区内。
4结论本文在区域成矿规律总结的基础上,查明了控矿要素和找矿标志,构建了找矿模型,并采用统计学和空间分析提取了预测要素,进而运用随机森林算法集成了多元预测要素,开展了找矿预测,取得以下结果:
(1)基于随机森林算法,深入挖掘Mn元素、沉积相、赋矿地层(上泥盆统榴江组和五指山组)出露、重力、航磁及向斜的空间分布特征及其与锰矿矿床的空间耦合性,以及不同控矿要素之间的相关性,构建二维锰矿资源预测分类模型。在构建模型中,本文加入了类权重参数,实现了正负样本的自动平衡。经过验证,该模型的袋外得分为0.998,表明该模型具有较好的泛化能力,且与逻辑回归和支持向量机相比,随机森林在研究区的应用效果更好。
(2)随机森林算法的特征重要性结果显示,赋矿地层、沉积相、Mn元素异常及锰矿露头位于特征重要性排序的前四,表明缓冲区赋矿地层和沉积相是下雷-土湖地区锰成矿的主要控制因素,Mn元素异常和锰矿露头缓冲区是重要的找矿标志,这与地质认识完全相符。
(3)采用该模型,在下雷-土湖地区开展了找矿预测,圈定成矿远景区6处。依据成矿概率,划分了远景区等级,其中Ⅰ类成矿远景区3个,Ⅱ类成矿远景区2个及Ⅲ类成矿远景区1个,为今后勘查工作部署提供参考。
表1下雷-土湖地区区域找矿模型Table 1 Regional mineral exploration model in the Xialei-Tuhu area序号
成矿要素
内容
1
大地构造位置
羌塘-样子-华南板块(Ⅳ)、扬子克拉通(Ⅳ-4)、滇黔桂被动陆源(Ⅳ-4-3)、富宁-那坡陆源沉降带(Ⅳ-4-3-2)、下雷坳拉谷(Ⅳ-4-3-2-3)
2
区域成矿带
滨太平洋成矿域(Ⅰ级)、华南成矿省(Ⅱ-16)、桂西-黔西南-滇东南北部Au-Sb-Hg-Ag-水晶-石膏成矿带(Ⅲ-88)、广西大新-武鸣 Sn-Cu-Pb-Zn-Mn-Al-煤成矿亚带(Ⅳ-12)、下雷-东平 Mn-Au-成矿带(Ⅴ-88-3-b)
3
成矿时代
晚泥盆世
4
岩相古地理
封闭、低能、还原的台盆环境
5
沉积建造
碳酸盐岩-硅质岩-泥岩建造
6
含锰岩系
上泥盆统榴江组第二段(D3l2)和五指山组第二段(D3w2)
7
蚀变特征
蔷薇辉石化、菱锰矿化、硅化、含锰碳酸盐化、黄铁矿化
8
成矿构造及成矿结构面
下雷-土湖同沉积断裂带内次级同沉积断层既控制次级成锰裂谷盆地的生成,也控制着深部富锰热液的运移通道,富锰热液沉积界面即成矿结构面
9
地球化学异常
Mn元素异常
10
地球物理异常
高低重力异常梯度带,与成矿构造吻合较好
表2成矿预测二分类混淆矩阵Table 2 Confusion matrix of two classification for metallogenic prediction对比项目
含矿(实际)
不含矿(实际)
含矿(预测)
TP
FP
不含矿(预测)
FN
TN
表3随机森林模型验证结果Table 3 Validation results of random forest model对比项目
含矿(实际)
不含矿(实际)
含矿(预测)
59
0
不含矿(预测)
0
425
精确度
1.00
1.00
召回率
1.00
1.00
F1值
1.00
1.00
特异性
1.00
1.00
总体准确率
1.00
表4下雷-土湖地区随机森林预测结果评价一览表Table 4 Summary of evaluation of random forest prediction results in the Xialei-Tuhu area预测要素
Ⅰ1
Ⅰ2
Ⅰ3
Ⅱ1
Ⅱ2
Ⅲ
地点
坡净南部
那国村-三叠岭地区
但山-岜排后地区
龙火岭东部
意江村北部
仰屯村东部
出露地层
上泥盆统五指
山组
上泥盆统五指
山组
上泥盆统五指
山组
上泥盆统榴
江组
上泥盆统五指
山组
上泥盆统五指山组
沉积相
台地内部相碳酸盐岩、硅质岩与泥岩沉积
台地内部至边缘相碳酸盐者夹硅质岩、泥砂质沉积
台地内部相碳酸盐岩、硅质岩与泥岩沉积
台地内部相碳酸盐岩、硅质岩与泥岩沉积
台地内部至边缘相碳酸盐者夹硅质岩、泥砂质沉积
台地内部至边缘相碳酸盐岩、硅质岩、泥砂质沉积
w(Mn)/10-6
3200~3709
2214~3014
2914~3014
2414~3314
2014~2214
1314
与露头缓冲区关系
距离大约0.1 km
距离大约0.7 km
距离大约3.9 km
距离大约14 km
距离大约19 km
距离大约6 km
与向斜核部缓冲区
关系
10%分布于上映-下雷向斜缓冲区内
84%分布于地州-湖润向斜缓冲区内
距离地州-湖润向斜缓冲区约185m
距离上映-下雷向斜缓冲区约13km
95%分布于意江向斜缓冲区内
均分布于那样-下谜向斜缓冲区内
剩余重力/10-5m/s2
-1.26~0
-4~-2
-5~-2
-3~-2
-2.58~0.79
-0.82~2
布格重力/10-5m/s2
-94~-92
-98~-96
-98
-84~-80
-98~-96
-92~-88
航磁ΔT化极/nT/250 m
10
2.57~20
-0.88~6
20~30
-0.39~8
40
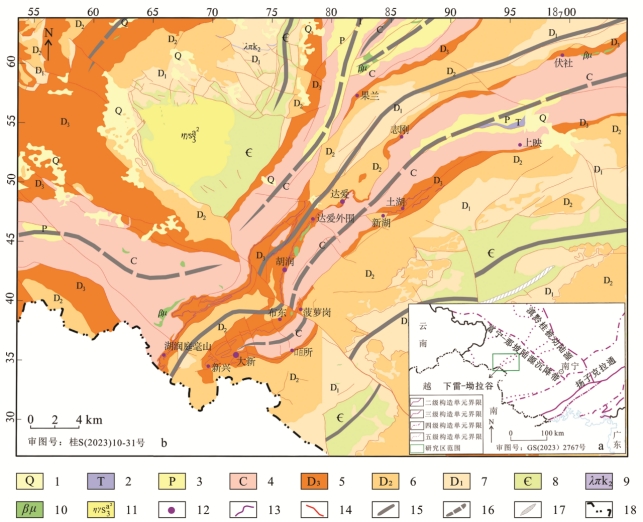
图1下雷-土湖地区大地构造图(a)与区域矿产地质图(b) (据赵品忠等,2021修改) 1—第四系;2—三叠系;3—二叠系;4—石炭系;5—泥盆系上统;6—泥盆系中统;7—泥盆系下统;8—寒武系;9—燕山期侵入岩;10—华力西期—印支期侵入岩;11—加里东期侵入岩;12—锰矿矿床点;13—锰矿露头线;14—断裂;15—背斜;16—向斜;17—基底褶皱;18—国界线 表1下雷-土湖地区区域找矿模型
Fig. 1 Tectonic map (a) and regional mineral geological map (b) of the Xialei-Tuhu area (modified from Zhao et al., 2021) 1—Quaternary; 2—Triassic; 3—Permian; 4—Carboniferous; 5—Upper Devonian; 6—Middle Devonian; 7—Lower Devonian; 8—Cambrian; 9—Yanshanian intrusive rocks; 10—Variscan—Indosinian intrusive rocks; 11—Caledonian intrusive rocks; 12—Manganese ore deposits; 13—Manganese ore outcrop line; 14—Fault; 15—Anticline; 16—Syncline; 17—Fold basement; 18—National boundary Table 1 Regional mineral exploration model in the Xialei-Tuhu area
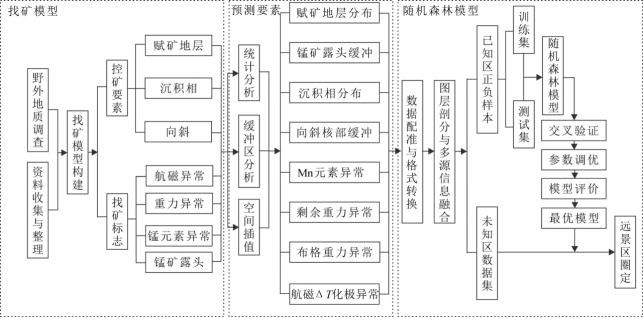
图2基于随机森林算法的矿产资源预测流程图
Fig. 2 Flowchart of mineral resource prediction based on random forest algorithm
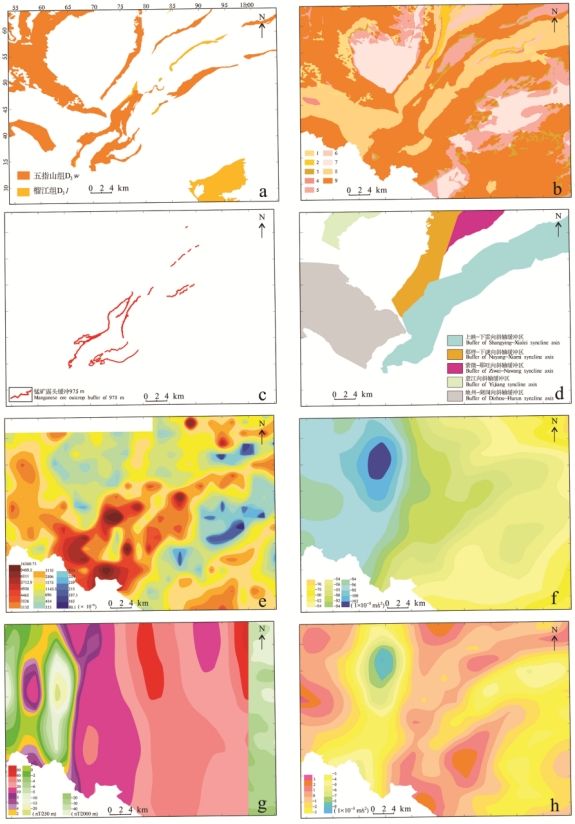
图3下雷-土湖地区预测要素空间分布图(底图据赵品忠等,2021修改) a.赋矿地层空间分布图;b.沉积相空间分布图;c.锰矿露头空间分布图;d.向斜缓冲区空间分布图;e. Mn元素空间分布图;f.布格重力异常分布图;g.航磁ΔT化极异常分布图;h.剩余重力异常分布图 1—河流相砂砾石与砂泥质沉积;2—台地边缘相碳酸盐岩沉积;3—半局限台地相白云岩夹碳酸盐岩相;4—台地内部相碳酸盐岩沉积;5—滨岸砂泥坪相泥岩与砂岩沉积;6—盆地相盐酸盐岩夹硅质岩沉积;7—盆地相砂泥质夹碳酸盐岩沉积;8—台地内部至边缘相碳酸盐岩夹硅质岩、泥砂质沉积;9—台地内部相碳酸盐岩硅质岩与泥岩沉积
Fig. 3 Spatial distribution map of predicted elements in the Xialei-Tuhu area (the original data referred from Zhao et al., 2021) a. Spatial distribution map of ore bearing strata; b. Spatial distribution map of sedimentary facies; c. Spatial distribution map of manganese ore outcrops; d. Spatial distribution map of syncline buffer zone; e. Spatial distribution map of Mn elements; f. Bouguer gravity anomaly distribution map; g. Aeromagnetic ΔT polarization anomaly; h. Distribution map of residual gravity anomaly 1—Fluvial deposition of sand, gravel and sandy-mud sediments in river environments; 2—Marginal facies carbonate deposition on plateau edge; 3—Semi-restricted platform facies with intercalated limestone and carbonate facies; 4—Carbonate deposition in the interior of plateaus; 5—Shoreline mudflat facies deposition of mudstone and sandstone; 6—Basin facies deposition of evaporites Intercalated with siliceous rocks; 7—Basin facies deposition of sandy-muddy sediments intercalated with carbonate rocks; 8—Carbonate and siliceous rocks intercalated with mud-sand sediments from plateau interior to margins; 9—Carbonate and siliceous rock intercalated with mudstone deposition in plateau interior

图4下雷-土湖地区锰矿露头附近地层产状 表2成矿预测二分类混淆矩阵
Fig. 4 Histogram of the attitude of the strata near the manganese ore outcrop in the Xialei-Tuhu area Table 2 Confusion matrix of two classification for metallogenic prediction
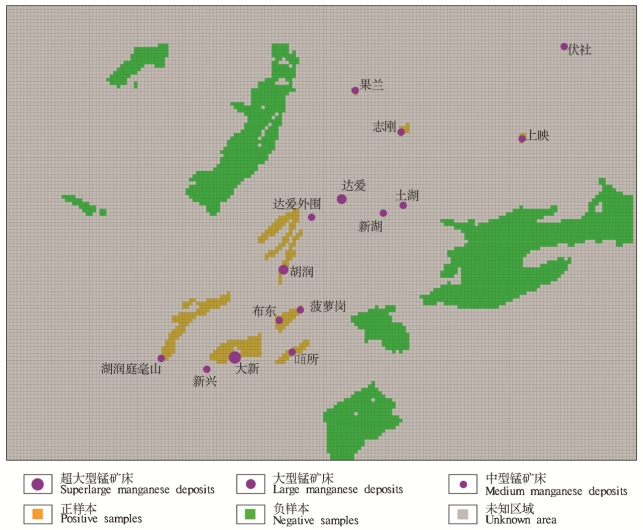
图5下雷-土湖正负样本分布图 表3随机森林模型验证结果
Fig. 5 Distribution of positive and negative samples in the Xialei-Tuhu area Table 3 Validation results of random forest model
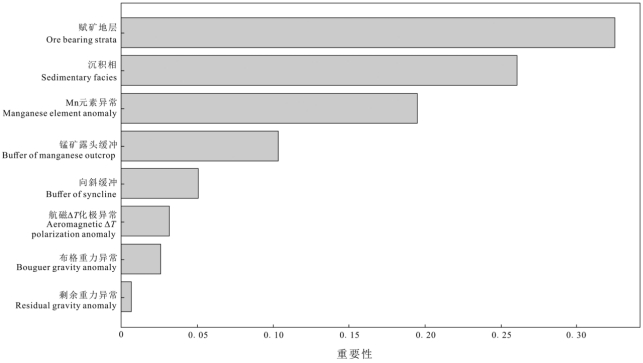
图6下雷-土湖随机森林算法特征重要性排序
Fig. 6 Ranking of feature importance in random forest algorithm in the Xialei-Tuhu area

图7下雷-土湖捕获概率曲线图
Fig. 7 Capture probability curve in the Xialei-Tuhu area

图8随机森林预测结果与各个控矿要素图层叠加图(据赵品忠等,2021修改) 1—河流相砂砾石与砂泥质沉积;2—台地边缘相碳酸盐岩沉积;3—半局限台地相白云岩夹碳酸盐岩相;4—台地内部相碳酸盐岩沉积;5—滨岸砂泥坪相泥岩与砂岩沉积;6—盆地相盐酸盐岩夹硅质岩沉积;7—盆地相砂泥质夹碳酸盐岩沉积;8—台地内部至边缘相碳酸盐岩夹硅质岩、泥砂质沉积;9—台地内部相碳酸盐岩硅质岩与泥岩沉积;10—锰矿矿床点;11—向斜;12—断裂;13—锰矿露头线;14—赋矿地层线; 15—地球物理异常;16—地球化学异常;17—Ⅰ类成矿远景区;18—Ⅱ类、Ⅲ类成矿远景区;19—国界线
Fig. 8 Random forest prediction results and overlay of various mineral control element layers(modified from Zhao et al., 2021) 1—Fluvial deposition of sand, gravel, and sandy-mud sediments in river environments; 2—Marginal facies carbonate deposition on plateau edge; 3—Semi-restricted platform facies with intercalated limestone and carbonate facies; 4—Carbonate deposition in the interior of plateaus; 5—Shoreline mudflat facies deposition of mudstone and sandstone; 6—Basin facies deposition of evaporites intercalated with siliceous rocks; 7—Basin facies deposition of sandy-muddy sediments intercalated with carbonate rocks; 8—Carbonate and siliceous rocks intercalated with mud-sand sediments from plateau interior to margins; 9—Carbonate and siliceous rock intercalated with mudstone deposition in plateau interior; 10—Manganese ore deposits; 11—Syncline;12—Fault; 13—Manganese ore outcrop line; 14—Ore bearing strata line; 15—Geophysical anomaly; 16—Geochemical anomaly; 17—ClassI metallogenic prospect area; 18—ClassⅡ andⅢ metallogenic prospect area; 19—National boundary
-
参考文献
摘要
进入地质大数据时代,如何深入挖掘与融合多源异构找矿空间大数据,成为当前矿产资源定量预测研究的热点。机器学习为提取和挖掘复杂数据中隐藏的难以识别的矿化信息和致矿异常信息的关联性,以及集成多源地学数据的致矿异常信息提供了有效工具。随机森林作为一种典型的机器学习算法,因其天然的并行特性、良好的模型可解释性、优秀的鲁棒性和泛化特性而被广泛应用于矿产资源预测。下雷-土湖是中国著名的以碳酸盐岩为容矿围岩的沉积型锰矿成矿区,区内产出中国首个超大型锰矿床——下雷锰矿,具有较大的找矿潜力。文章以下雷-土湖地区为研究对象,基于随机森林算法,深入挖掘Mn元素、沉积相、上泥盆统榴江组和五指山组出露、重力、航磁和向斜的空间分布特征及其与锰矿矿床的空间的耦合相关性,以及不同控矿要素之间的相关性,构建二维锰矿资源预测分类模型。在构建模型中,文章加入类权重参数,实现了正负样本的自动平衡。经过验证,该模型的袋外得分为0.998,表明该模型具有较好的泛化能力,且与逻辑回归和支持向量机相比,随机森林在研究区的应用效果更好。应用该模型对未知区进行找矿预测,圈定找矿远景区6处。
Abstract
In the era of geological big data, the in-depth exploration and integration of heterogeneous multi-source exploration spatial big data have become hot topics in current research on quantitative prediction of mineral resources. Machine learning provides effective tools for extracting and mining the correlation between difficult-to-identify mineralization information and mineralization anomaly information hidden in complex data, as well as integrating mineralization anomaly information from multiple sources of geoscience data. As a typical machine learning algorithm, random forest is widely used in mineral resource prediction due to its natural parallel characteristics, good model interpretability, excellent robustness and generalization characteristics. Xialei-Tuhu is a well-known sedimentary manganese mineralization area in China, with carbonate rock as the ore-hosting surroun-ding rock. The area produces China's first super-large manganese deposit—Xialei manganese deposit, which still has great potential for mineral exploration. The paper takes the Xialei-Tuhu area as the research object, and based on the random forest algorithm, deeply explores the spatial distribution characteristics of Mn elements, sedimentary facies, the outcrop of the Upper Devonian Liujiang Formation and Wuzhishan Formation, gravity, aeromagnetism, and syncline, as well as their coupling correlations with the manganese deposit in space. Furthermore, it explores the correlations between different ore-controlling factors to construct a two-dimensional manganese resource prediction and classification model. In the construction of the model, this article added class weight parameters to achieve automatic balancing of positive and negative samples. After verification, the out of bag score of the model is 0.998, indicating that the model has good generalization ability, and compared with logistic regression and support vector machine, the application effect of random forest in the study area is better. This model was used to predict mineralization in unknown areas, and 6 mineralization prospects were delineated.
